株式会社翔泳社さんより、Tyamaさんが書いたPlugin部分(一番濃いんじゃないかと)も含めて「Grails徹底入門」が発刊されます!2008年8月25日だそうです。
みなさん、買いに行ってGrailsを楽しみましょう!
Groovy in Actionの日本語翻訳版もそろそろでます(お疲れ様でした)ので、これでとりあえず日本で広まるためのネタが世に出始めますね。
いろんな技術がある中、何でもいいとは思うんですが、うわべだけじゃなく、その奥深いところまで足を踏み入れていくのって勇気もいるし、エネルギーもいると思うんですが、ましてやそれを出版物として世の中に出すという責任とか、どうやったら読んだ人に伝えられるか、とかいろいろ悩みながら書いておりました。
三回ぐらい校正を手伝ったのですが、Grailsだけあって普通の技術本とは違うんだよな、と思わせるところが多くって、GrailsとかGroovyとかは、いろいろ簡単にできますよ、っていうRails的な部分よりは、Webアプリケーションに必要なSpringとかHibernateとか、そういう基盤となる技術も自ずと見えてくるところがいいのかなと思います。
フレームワークにたよってしまう前に、やっぱり知らなくてもいいけど、知っておいた方がいいこともいっぱいあるんだなと、ただ、ここから先は、研究心とか探求心がないと、中途半端に終わってしまう。でも、そこを超えれば、今まで何度教えてもらっても分からなかったこととかが、「ああなんだそういうことなんだ」みたいに軽く受け入れられるかもしれない、という希望が見えるよなあと思います。
Tyamaさんの方が6ヶ月先に生まれているので、その分僕の理解は6ヶ月後なわけなのですが、何度も読むと、ちょっとずつ分かってきたりする自分が楽しい。そして、「コイツあほやな」と本気で思えてしまうほど、こだわり、神経質さが見えてくるところもおもしろい。これは、まさに技術本ではなく、見方を変えると、哲学書だなと思えます。まだ他の人が書いたところは読ませてもらってないので分からないですが、Grailsの魅力がいろんな人に伝わればいいなと
思ってます。
文芸書の評論集とかたまに読むんですが、世にあるシステムを哲学的に読み解く、っていうのもおもしろい気がするなとふと思いました。
どうしてこの技術を選んだのかとか、なぜこういう仕様にしたのかとか、そういうところに作者の生い立ち、経歴をキーにして、意図を読み解くみたいな、、、そうされてもいいぐらいの作品(粗くてもいいと思うけど)にこだわりを持って仕上げるっていう気持ちってこれからのSEやSI、プログラマーに必要なんじゃないかなと、よりアーティスティックな世界になればいいのにと思います。
今回は、労をねぎらってTyamaリスペクトになってしまった。。。
2008年7月26日土曜日
2008年7月15日火曜日
DTP作業手順書がないからでしょ
ああ、担当者間の電話を聞いている。
振った本人も作業手順を覚えていない。
作業した人もうる覚えで対応している。
「おいおいおいおい」
だから、DTP作業手順書がいるじゃないかと、いつも言っているのだよ。
その時間が無駄じゃん。
めんどくさい、と思うのかな?
そうなっちゃった時の方がもっとめんどくさいじゃない。。。
振った本人も作業手順を覚えていない。
作業した人もうる覚えで対応している。
「おいおいおいおい」
だから、DTP作業手順書がいるじゃないかと、いつも言っているのだよ。
その時間が無駄じゃん。
めんどくさい、と思うのかな?
そうなっちゃった時の方がもっとめんどくさいじゃない。。。
2008年7月13日日曜日
Grails Unit Testの中間まとめ
Domainに対して基本的なCreateやDelete、Copyなどが正常に動作するかどうかを、ControllerとかViewを作り始める前に、アプリケーションが肥大化する前に、最初から確認しておく(test-appで確認し続ける)ことは、データが中心であると考えた時に、とても重要なので、そこを集中してやってみようと思ってやり始めた。テストドリブンであり、ドメインドリブンを基本としたアジャイルな開発を目指したい。
ここまでの流れをまとめると、、、
1.この案件の中心的存在となるDomainを決めて、今まで聞き取った要件に合わせて、Domain同士がどう関連するかのイメージ図を、5回ぐらい書き直しながら作成した。
Domainの属性は、徐々にFixしていくものとして、最低限必要なものだけをピックアップした。
何が本当に必要なデータなのかを見極めるフェーズだ。
2.モデリングと照らし合わせて、業務フローを確認しながらまた数回書き直した。
3.grails create-appでアプリケーションを作成し、create-domain-classでDomainを作っていく。順番としては、一番重要なデータから見て、一番端にあるものからだ。
4.例えば、複数のDomainがHasMany、belongsToしている場合、各Domain単位でのTestを書いていると面倒なので、あとで分けることを想定して、DomainsTests.groovyと、そのテストデータをTestDataSet.groovyに作成する。(ともにtest/integrationの中)
5.DomainTests.groovyの中の先頭部分には、TestDatasの中のクラスを見に行けるように、下記を記述した。このClassLoaderを回さないと、testの中のクラスに辿り着けない模様。
class DomainsTests extends GroovyTestCase {
def gcl = new GroovyClassLoader()
def testDataClazz = gcl.parseClass(new File("test/integration/testDataSet.groovy")).newInstance()
void setUp(){
testDataClazz.testdataSetup()
}
}
6.TestDataSet.groovyには、、、
class TestDataSet {
def testdataSetup() {
def book = new Book()
book.name = "testBook"
}
}
7.と、しておけば、ここのSetupController.groovyとかで、このテストデータを使い回せる。
8.基本としてテストを書いたのは、
データ登録チェック、データ削除の際のHasMany、belongsToの違いによる挙動のチェック。
このようにやった結果、テストを書きながら、業務フローや画面遷移も想像しながら、Domain周りを固めていける。そして、後々細かい要件が出てくる際に、ここをベースにいけばよいので効き目があると思う。ただ、物事はシンプルさを貫き通さなければならない、ということを忘れないようにやらなければいけないと、もう一回心に誓うことも忘れないように。
9.あと、Controllerも作っておく。でも、Scaffoldに徹する。
class BookController {
def scaffold = Book
}
10.はじめてのrun-app
Scffoldなので微妙だけど、とりあえず動かして、データ登録の流れを確認。アプリケーションのイメージをふくらませる。
11.そして、Template-pluginをinstallしておく。generate-allすると、i18n用のタグをGSPに挟んでくれる。
12.そろそろ、generate-allで、controllerとviewを吐きだす。
また続き書きます。
ここまでの流れをまとめると、、、
1.この案件の中心的存在となるDomainを決めて、今まで聞き取った要件に合わせて、Domain同士がどう関連するかのイメージ図を、5回ぐらい書き直しながら作成した。
Domainの属性は、徐々にFixしていくものとして、最低限必要なものだけをピックアップした。
何が本当に必要なデータなのかを見極めるフェーズだ。
2.モデリングと照らし合わせて、業務フローを確認しながらまた数回書き直した。
3.grails create-appでアプリケーションを作成し、create-domain-classでDomainを作っていく。順番としては、一番重要なデータから見て、一番端にあるものからだ。
4.例えば、複数のDomainがHasMany、belongsToしている場合、各Domain単位でのTestを書いていると面倒なので、あとで分けることを想定して、DomainsTests.groovyと、そのテストデータをTestDataSet.groovyに作成する。(ともにtest/integrationの中)
5.DomainTests.groovyの中の先頭部分には、TestDatasの中のクラスを見に行けるように、下記を記述した。このClassLoaderを回さないと、testの中のクラスに辿り着けない模様。
class DomainsTests extends GroovyTestCase {
def gcl = new GroovyClassLoader()
def testDataClazz = gcl.parseClass(new File("test/integration/testDataSet.groovy")).newInstance()
void setUp(){
testDataClazz.testdataSetup()
}
}
6.TestDataSet.groovyには、、、
class TestDataSet {
def testdataSetup() {
def book = new Book()
book.name = "testBook"
}
}
7.と、しておけば、ここのSetupController.groovyとかで、このテストデータを使い回せる。
8.基本としてテストを書いたのは、
データ登録チェック、データ削除の際のHasMany、belongsToの違いによる挙動のチェック。
このようにやった結果、テストを書きながら、業務フローや画面遷移も想像しながら、Domain周りを固めていける。そして、後々細かい要件が出てくる際に、ここをベースにいけばよいので効き目があると思う。ただ、物事はシンプルさを貫き通さなければならない、ということを忘れないようにやらなければいけないと、もう一回心に誓うことも忘れないように。
9.あと、Controllerも作っておく。でも、Scaffoldに徹する。
class BookController {
def scaffold = Book
}
10.はじめてのrun-app
Scffoldなので微妙だけど、とりあえず動かして、データ登録の流れを確認。アプリケーションのイメージをふくらませる。
11.そして、Template-pluginをinstallしておく。generate-allすると、i18n用のタグをGSPに挟んでくれる。
12.そろそろ、generate-allで、controllerとviewを吐きだす。
また続き書きます。
2008年7月12日土曜日
Grails/GroovyとTextMate
面白いものを教えてもらったので。
TextMateにBundleの設定しないとだめですけど。

def sss="aaa"
sss.getClass().methods.each {
println it.name
}
を書いてみて、選択して、TextMateにgroovyを走らせると、↓な感じで、なんか出る!
APIリファレンスを見る前に確認できてよい。

TextMateにBundleの設定しないとだめですけど。

def sss="aaa"
sss.getClass().methods.each {
println it.name
}
を書いてみて、選択して、TextMateにgroovyを走らせると、↓な感じで、なんか出る!
APIリファレンスを見る前に確認できてよい。

InDesignにXMLをとりこんでみる
できるって分かってて実験したかどうかも忘れてしまったので、次こそ忘れないぞ、ということで書いておこうと思います。
とりあえず、単純なXMLを読み込んで、確認です。
参考URLはここです。
目標:
1.XMLのタグ内の文字列が、指定したテキストフレームに取り込まれること。
2.指定した段落スタイルが適用されること。
3.画像が取り込まれること。(上記参考URLを参考にしてくだし。file://で指定するだけです。)
4.複数の要素を1つの枠に入れられること。
InDesignのXML取り込みの概要は、以下の通り。
・InDesign上に、テキストフレームや画像フレームを置いて、InDesignドキュメントを準備する。
・XMLを準備する。
・「構造」を表示させて、XMLを取り込む。
・取り込んだXMLの要素を、InDesignのフレームにドラッグ&ドロップする。
以上
1回このマッピング(XML要素←→InDフレーム)ができてしまえば、別のXMLを取り込むと内容が入れ替わる。まぁべんり!
あとは、JSなどで、一気にXMLを回して取り込んじゃえばなおかっこよい。
下準備がめんどくさいって、言ったらだめですよ。この機能を使う意味ないですからね。
コンピュータは、人の頭の中を読んではくれないです。指示を与えないと動きません、です。
DTPって、やればできてしまうので、ゴリゴリやっちゃうんですが、
こういう下準備、段取り上手が仕事を速くするとホントに思う今日この頃。
いつまでもうだうだやってんじゃねえよ、と自分に喝を入れて取り組みましょう。
それでは開始…
1.InDesignドキュメントを準備します。
InDを立ち上げて、「ファイル」→「新規」→「ドキュメント」を選択して、
何も考えずに、Enterを2回押すと、まっしろいドキュメントできました!
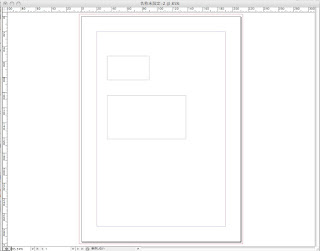
2.ツールバーの「T(文字)」ツールをクリックして、適当に、テキストフレームを作成。
サンプルなので、これを仮に枠Aと枠Bとして、2つ作ってください。
↓こんな感じです。(適当です)
3.XMLを準備します。(適当です)
import.xmlとして保存しておきましょう。
<?xml version="1.0" encoding="UTF-8"?>
<import>
<a>Aタグ</a>
<b>
<c>Cタグ</c>
<d>Dタグ</d>
</b>
</import>
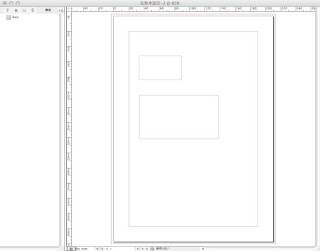
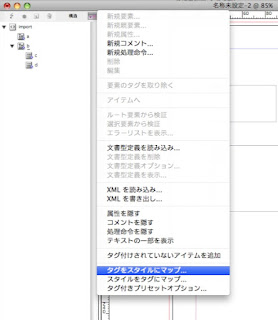
4.InDesignの「表示」メニュー→「構造」→「構造を表示」を選択します。
↓こんな感じです。
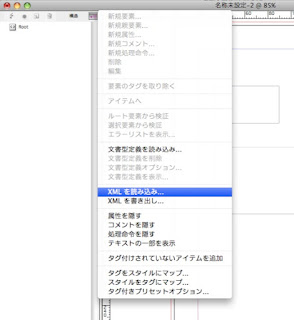
5.XML読み込みメニューを選択します。
↓メニューはちょっとわかりにくいところにあります。こんな感じです。(構造ビューの右↑です)
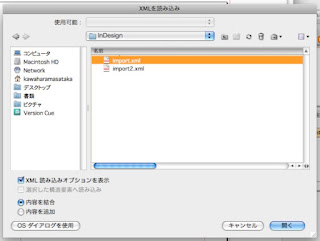
6.XMLを選択します。さっきのimport.xmlです。
設定とか、いろいろありますが、とりあえず無視して、デフォルトのままいきましょう。
あとでいろいろ触ってみてください。
7.またなんか設定ダイアログが表示されました。
とりあえず無視して、そのままEnterしましょう。
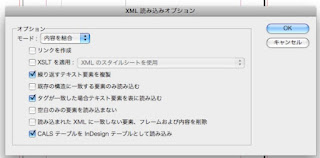
8.はい、そうすると、出ましたか?XMLのツリー構造が構造ビューに表示されます。
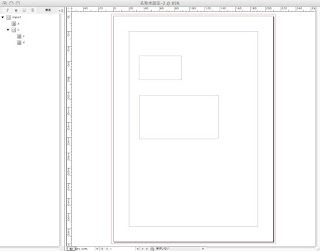
9.面白くなってきましたねえ。。。では、左の構造ビューの「a」のところから、ドキュメントの枠A(上の方です)に、ドラッグ&ドロップしてやってください。
これがマッピング操作です。
↓イメージわかりにくいです。(Macのプレビューでタイマーで撮ったんだけどなあ。。。)
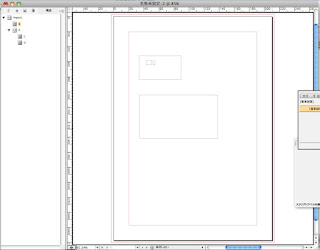
10.今度は、2つの要素を1つの枠にぶっこみます。
この場合は、CとDの親要素であるBをドラッグ&ドロップで下の方の枠に入れます。
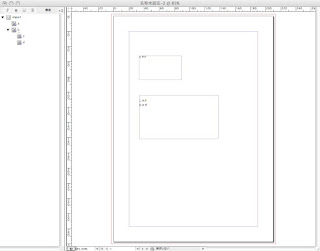
11.要素にそれぞれ段落スタイルが適用されるようにしてみましょう。
段落スタイル1,2,3を、基本をコピーして作成し、適当にフォント、フォントサイズを変更してください。
そのスタイルを、aとcとdにマッピングします。
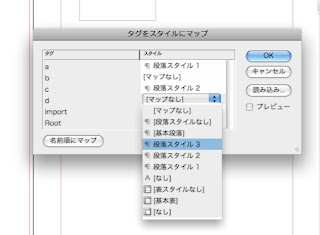
すみません、時間がなくなってきたので、はしょりに入ります。
12.適用されるとこんな感じ。
要素ごとにスタイルが適用されました。
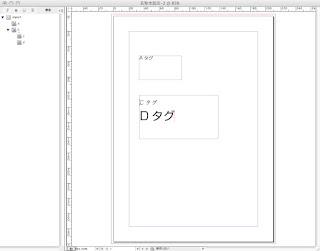
13.さぁ、XMLを使う醍醐味です。
XMLを入れ替えて内容を入れ替えましょう。
<?xml version="1.0" encoding="UTF-8"?>
<import>
<a>Aタグ入れ替え</a>
<b>
<c>Cタグ入れ替え</c>
<d>Dタグ入れ替え</d>
</b>
</import>
14.ほら、変わった!(一部溢れてますね。こういうのもInD側の設定次第で調整できるんじゃないかな)
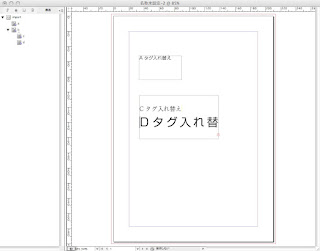
以上です。
結構簡単にできますね。
どのレベルまで実現したいかを、じっくり機能を試しながらやってみて決めていくのがいいと思います。
とりあえず、単純なXMLを読み込んで、確認です。
参考URLはここです。
目標:
1.XMLのタグ内の文字列が、指定したテキストフレームに取り込まれること。
2.指定した段落スタイルが適用されること。
3.画像が取り込まれること。(上記参考URLを参考にしてくだし。file://で指定するだけです。)
4.複数の要素を1つの枠に入れられること。
InDesignのXML取り込みの概要は、以下の通り。
・InDesign上に、テキストフレームや画像フレームを置いて、InDesignドキュメントを準備する。
・XMLを準備する。
・「構造」を表示させて、XMLを取り込む。
・取り込んだXMLの要素を、InDesignのフレームにドラッグ&ドロップする。
以上
1回このマッピング(XML要素←→InDフレーム)ができてしまえば、別のXMLを取り込むと内容が入れ替わる。まぁべんり!
あとは、JSなどで、一気にXMLを回して取り込んじゃえばなおかっこよい。
下準備がめんどくさいって、言ったらだめですよ。この機能を使う意味ないですからね。
コンピュータは、人の頭の中を読んではくれないです。指示を与えないと動きません、です。
DTPって、やればできてしまうので、ゴリゴリやっちゃうんですが、
こういう下準備、段取り上手が仕事を速くするとホントに思う今日この頃。
いつまでもうだうだやってんじゃねえよ、と自分に喝を入れて取り組みましょう。
それでは開始…
1.InDesignドキュメントを準備します。
InDを立ち上げて、「ファイル」→「新規」→「ドキュメント」を選択して、
何も考えずに、Enterを2回押すと、まっしろいドキュメントできました!
2.ツールバーの「T(文字)」ツールをクリックして、適当に、テキストフレームを作成。
サンプルなので、これを仮に枠Aと枠Bとして、2つ作ってください。
↓こんな感じです。(適当です)

3.XMLを準備します。(適当です)
import.xmlとして保存しておきましょう。
<?xml version="1.0" encoding="UTF-8"?>
<import>
<a>Aタグ</a>
<b>
<c>Cタグ</c>
<d>Dタグ</d>
</b>
</import>
4.InDesignの「表示」メニュー→「構造」→「構造を表示」を選択します。
↓こんな感じです。

5.XML読み込みメニューを選択します。
↓メニューはちょっとわかりにくいところにあります。こんな感じです。(構造ビューの右↑です)

6.XMLを選択します。さっきのimport.xmlです。
設定とか、いろいろありますが、とりあえず無視して、デフォルトのままいきましょう。
あとでいろいろ触ってみてください。

7.またなんか設定ダイアログが表示されました。
とりあえず無視して、そのままEnterしましょう。

8.はい、そうすると、出ましたか?XMLのツリー構造が構造ビューに表示されます。

9.面白くなってきましたねえ。。。では、左の構造ビューの「a」のところから、ドキュメントの枠A(上の方です)に、ドラッグ&ドロップしてやってください。
これがマッピング操作です。
↓イメージわかりにくいです。(Macのプレビューでタイマーで撮ったんだけどなあ。。。)

10.今度は、2つの要素を1つの枠にぶっこみます。
この場合は、CとDの親要素であるBをドラッグ&ドロップで下の方の枠に入れます。

11.要素にそれぞれ段落スタイルが適用されるようにしてみましょう。
段落スタイル1,2,3を、基本をコピーして作成し、適当にフォント、フォントサイズを変更してください。
そのスタイルを、aとcとdにマッピングします。


すみません、時間がなくなってきたので、はしょりに入ります。
12.適用されるとこんな感じ。
要素ごとにスタイルが適用されました。

13.さぁ、XMLを使う醍醐味です。
XMLを入れ替えて内容を入れ替えましょう。
<?xml version="1.0" encoding="UTF-8"?>
<import>
<a>Aタグ入れ替え</a>
<b>
<c>Cタグ入れ替え</c>
<d>Dタグ入れ替え</d>
</b>
</import>
14.ほら、変わった!(一部溢れてますね。こういうのもInD側の設定次第で調整できるんじゃないかな)

以上です。
結構簡単にできますね。
どのレベルまで実現したいかを、じっくり機能を試しながらやってみて決めていくのがいいと思います。
2008年7月8日火曜日
Branddoozie ちょっと見てみる
ここにあるように、
"Technologies
BrandDoozie is powered by patent-pending proprietary technology as well as Adobe Flex and CS3 InDesign Server."
ということで、Adobe FlexとCS3 InDesign Serverを使っとりますとのこと。
もっさり感はあるものの、名古屋弁風に言うと「まぁ、そうだわな」といったところ。

上のスクリーンショットは、Step1〜3のうちの「さぁ〜んっ」のところ。
Step1、2で、自分の名前とか住所とか、デザイン、スタイル及びテンプレートの基本的な情報を入れていく。
Step3では、実際のドキュメントの中がブロック分けされているので、その部分の文字を編集する、という感じです。
試した感でいきます。
1.まんず日本語入らない。(まあ仕方ない)
2.編集結果の更新で、1P分で約5〜10秒
InDesignでレンダリング→JPEGとかしてんだろうな。。。
3.PDFは、Betaにつき落ちてきまへん。
4.データ(情報)が連携している感を出している。
で、何?ということなんですが、第一印象では、Flexでやりすぎると、見た人の想像力を欠いてしまうんじゃないかと思ってしまう。これで完成していると思われるのは、ここの会社の意図ではないと。
要するに、FlexとCS3使うと、こんなことできまっせ、ということだろうと思います。
まあ、でもちょっとやりすぎじゃないかな。。。WEB Publishingが、インパクト優先でこっちの方向に行ってしまうのはよくないんじゃないかと個人的に思います。
"Technologies
BrandDoozie is powered by patent-pending proprietary technology as well as Adobe Flex and CS3 InDesign Server."
ということで、Adobe FlexとCS3 InDesign Serverを使っとりますとのこと。
もっさり感はあるものの、名古屋弁風に言うと「まぁ、そうだわな」といったところ。

上のスクリーンショットは、Step1〜3のうちの「さぁ〜んっ」のところ。
Step1、2で、自分の名前とか住所とか、デザイン、スタイル及びテンプレートの基本的な情報を入れていく。
Step3では、実際のドキュメントの中がブロック分けされているので、その部分の文字を編集する、という感じです。
試した感でいきます。
1.まんず日本語入らない。(まあ仕方ない)
2.編集結果の更新で、1P分で約5〜10秒
InDesignでレンダリング→JPEGとかしてんだろうな。。。
3.PDFは、Betaにつき落ちてきまへん。
4.データ(情報)が連携している感を出している。
で、何?ということなんですが、第一印象では、Flexでやりすぎると、見た人の想像力を欠いてしまうんじゃないかと思ってしまう。これで完成していると思われるのは、ここの会社の意図ではないと。
要するに、FlexとCS3使うと、こんなことできまっせ、ということだろうと思います。
まあ、でもちょっとやりすぎじゃないかな。。。WEB Publishingが、インパクト優先でこっちの方向に行ってしまうのはよくないんじゃないかと個人的に思います。
XSLformatterの出力は黒をオーバープリントには今のところできない模様
2008年7月8日現在、実装検討中とのことです。
TrueFlow側というかRIP側の設定で吸収がデフォと考えれば、特に必要というわけでもないということなのかな。
TrueFlow側というかRIP側の設定で吸収がデフォと考えれば、特に必要というわけでもないということなのかな。
WPSでOTFの異体字を適用する
WPSで外字を使いたい場合は、といった感じで、こちらからお知らせしている番号を入れていただきます。
このタグと番号を、DTPアプリが搭載している外字番号に関連付けて出力させています。
外字のエリアには、色々ありまして、
1.DTPアプリ側がもともと持っている外字エリア
2.このDTPアプリを使うユーザが登録するユーザ外字エリア
というものがあります。
さらに、外字を複数のフォントで使いたい場合には、それごとに持たせる必要があります。
DTPアプリによっては、ユーザ外字にあたるものを、フォントとして作成したりする場合もあります。
ちなみに、EdianWingの場合は、1外字にフォントの階層を持たせることができるので、使いたいフォント分の文字を1コードに収められます。書体を変えるだけで外字の見た目も変更されるということになります。
(MC-B2の場合は、また今度。)
一昔前までは、フォントメーカーが準備した文字が、なかなかなくって、結構なたくさん外字を登録していました。さらにシステム上決められた範囲のコードエリアしか使えないため、苦渋の策で、外字を入れ替えたりと、大変でした。
ですが、OTF(オープンタイプフォント)の登場によって、かなりの文字がカバーされることになり、ユーザ外字やユーザ外字フォントを準備する必要がなくなりました。
たとえば、印刷するときには、その外字フォントも同梱しなければらなない、など、印刷事故の原因の一つでしたが、その点がかなり改善されました。
アプリケーションによりますが、「吉」という字を入力した後、その異体字を選択項目から選択する、というような方法で、今まで出せなかった文字が出せるようになっています。
ですが、印刷のときに、出るかどうかというのは、また出力方法によりますので、注意が必要です。
WPS(現行運用バージョン)の場合は、ユーザ外字、異体字にかかわらず、リストから確認できる仕上がりの状態で、外字が適格に出力されていれば、印刷ではアウトライン化されていますので、不具合は出ることはありません。
ユーザに一覧表を渡したいですが、なかなかのボリュームなので、まだ渡していないです。
とりあえず、これに関わるお問い合わせ件数も少ないので、都度コード番号をお知らせしています。
このタグと番号を、DTPアプリが搭載している外字番号に関連付けて出力させています。
外字のエリアには、色々ありまして、
1.DTPアプリ側がもともと持っている外字エリア
2.このDTPアプリを使うユーザが登録するユーザ外字エリア
というものがあります。
さらに、外字を複数のフォントで使いたい場合には、それごとに持たせる必要があります。
DTPアプリによっては、ユーザ外字にあたるものを、フォントとして作成したりする場合もあります。
ちなみに、EdianWingの場合は、1外字にフォントの階層を持たせることができるので、使いたいフォント分の文字を1コードに収められます。書体を変えるだけで外字の見た目も変更されるということになります。
(MC-B2の場合は、また今度。)
一昔前までは、フォントメーカーが準備した文字が、なかなかなくって、結構なたくさん外字を登録していました。さらにシステム上決められた範囲のコードエリアしか使えないため、苦渋の策で、外字を入れ替えたりと、大変でした。
ですが、OTF(オープンタイプフォント)の登場によって、かなりの文字がカバーされることになり、ユーザ外字やユーザ外字フォントを準備する必要がなくなりました。
たとえば、印刷するときには、その外字フォントも同梱しなければらなない、など、印刷事故の原因の一つでしたが、その点がかなり改善されました。
アプリケーションによりますが、「吉」という字を入力した後、その異体字を選択項目から選択する、というような方法で、今まで出せなかった文字が出せるようになっています。
ですが、印刷のときに、出るかどうかというのは、また出力方法によりますので、注意が必要です。
WPS(現行運用バージョン)の場合は、ユーザ外字、異体字にかかわらず、リストから確認できる仕上がりの状態で、外字が適格に出力されていれば、印刷ではアウトライン化されていますので、不具合は出ることはありません。
ユーザに一覧表を渡したいですが、なかなかのボリュームなので、まだ渡していないです。
とりあえず、これに関わるお問い合わせ件数も少ないので、都度コード番号をお知らせしています。
PCで携帯のUserAgentを確認する方法
Safariです。環境設定→メニューバーに開発メニューを表示にチェック
http://kazumich.com/index.php?ID=4096
開発メニューから、ユーザーエージェントでどれかを選択
ない場合には、http://www.openspc2.org/userAgent/などで、
それぞれのUserAgentをコピーして、その他のところにペースト
http://kazumich.com/index.php?ID=4096
開発メニューから、ユーザーエージェントでどれかを選択
ない場合には、http://www.openspc2.org/userAgent/などで、
それぞれのUserAgentをコピーして、その他のところにペースト
Google DocsでOfficeいらずになれるか?
ま、Officeを共有ならそれでいいんですけどね。
Mac版Officeもそこそこなんですが、、、ちょっとGoogleDocsを使う頻度が高くなってきた。
Office製品は、もともとローカルファイル作業の概念のものなので、使う人の意識が、私目を筆頭に共有を意識していない。実に様々な派生とバージョンによって管理されているとは言えない。
GoogleDocsの利点・用途は、次のようなものだと勝手に推測する。
1.共同作業したい場合、その場所と機能を提供してくれる。
2.自分のPCやHD、自社のファイルサーバ、ネットワーク、セキュリティの信頼度がGoogle様より下回っている。
まず、エクセルシートのようなものを共同作業してみると、相手が触っているセルの色が変わって、編集してんだな、、、とわかる。
ワードらしきものは、文章をマージ、Diffしてくれる。
もちろんバージョン管理もしてくれる。
エクセル、ワード独特の高機能を使わないで、Wikiはちょっと、CMSはちょっと、というような、とりあえず共有して作業進めようぜ、的な場面にはもってこい。なんか楽しいしね。
ラベル付け、ディレクトリ(っぽい)のもいけてるし、公開範囲を決められたり、特に不自由さを感じない。ただ、正式に提出する資料までは無理だと思います。
あとは、ネットワーク無いとダメは諦める。Google様が音信不通になると、ドキドキする、といったところでしょうか。
Mac版Officeもそこそこなんですが、、、ちょっとGoogleDocsを使う頻度が高くなってきた。
Office製品は、もともとローカルファイル作業の概念のものなので、使う人の意識が、私目を筆頭に共有を意識していない。実に様々な派生とバージョンによって管理されているとは言えない。
GoogleDocsの利点・用途は、次のようなものだと勝手に推測する。
1.共同作業したい場合、その場所と機能を提供してくれる。
2.自分のPCやHD、自社のファイルサーバ、ネットワーク、セキュリティの信頼度がGoogle様より下回っている。
まず、エクセルシートのようなものを共同作業してみると、相手が触っているセルの色が変わって、編集してんだな、、、とわかる。
ワードらしきものは、文章をマージ、Diffしてくれる。
もちろんバージョン管理もしてくれる。
エクセル、ワード独特の高機能を使わないで、Wikiはちょっと、CMSはちょっと、というような、とりあえず共有して作業進めようぜ、的な場面にはもってこい。なんか楽しいしね。
ラベル付け、ディレクトリ(っぽい)のもいけてるし、公開範囲を決められたり、特に不自由さを感じない。ただ、正式に提出する資料までは無理だと思います。
あとは、ネットワーク無いとダメは諦める。Google様が音信不通になると、ドキドキする、といったところでしょうか。
2008年7月3日木曜日
組版エンジンの自動組版サーバ的な対応を(勝手に)比較
ご依頼ありまして、忘れてましたので、アップ。
うーん、最近ペースが悪い。
WEB入稿→自動組版→出力の流れに対応できる組版エンジンは、どんなものがあるか、
日進月歩、試行錯誤な毎日ですが、現状ということで。
その筋の方は、コメントして構いませんので、よろしくお願い申し上げます。
///XSLFormatter
アンテナハウス製品(いつもお世話になってます。)
xsl-foの標準仕様+axf拡張で、FOに変換して取り込む。
WEB-Serviceオプションも用意されているので、WEBサービス経由で操作させることも可能。
あとは、コマンドキックとかもできます。
なんといってもPDF出力がデフォなので、PDF出力を最終と考えるなら、
組版→出力の流れは一番速いということになる。
日本語組版的な細かい組版仕様はできないことがある。
最近はまっているのでは、文字のボックスの一部に画像をおいて、そこを排除して文字を回り込ませるあたりは、できないレイアウトがある。
サーバ版という位置づけがこの製品の適切な区分けにはならないと思うが、販売形態としては、スタンドアロン版とサーバ版とある。サーバ版は、1CPUライセンスごと。不特定多数のインターネット利用の場合は、別途の構成がある。
///EdianWing
キヤノンITソリューションズ製品(いつもお世話になってます。キヤノンシステムソリューションズから改名。もとは住友金属。さらに開発しているのは、、、どこだっけ、、、えーと、桐とかの、、、いったことあるんだけど、、、物忘れ激しい、、、あ、管理工学研究所、そうそう)
もともとが、バッチ処理系に長けている製品なので、組版表現は100%(多分)トリガーテキストと呼ばれる文字データで制御できる。
ただし、見た目の判断によるオペレーションレベルまではトリガーテキストではいけない。
ただ、操作制御を行う「スクリプト」なるものがオプションであって、それを使うと、オペレベルのこともスクリプトに書いて実行すれば実現する、というレアな製品。
ちなみに、一般利用としてのAPIは公開されていないが、入稿システムに使うのであれば、WEB2Edian(今もあるのかな)なる、JAVAからソケット通信できるオプションがある。
問題は、価格が高すぎることと、PDFが直接吐けない。
そうなると、組版→EPS(PS)出力→PDF変換でPDF出力となる。
Adobe製品のDistillerをサーバに仕込むとしこたまお金をとられるので、小さい規模の仕組みには使えない。
ただ、結構丈夫なのはすばらしい。組版も速い。
このアプリをDTPとして、他のIDやQXと同等にしか使わないとするなら経営者的にNG。
だって、1台350万円もするんすよ。。。ちなみにうちは10台も20年近く使ってますが、台数の内訳はDTPと自動組版の半々になりましたね。
個人的な愛着もあってNo.1。(表作るの楽だし^^)
///Edicolor
同上の会社製品。地方新聞、広報誌などで現役で戦っておられる。IDへ移行するところもあるが、根強いファンがいるのも事実。
こちらは管理工学研究所ではなく、純日本製のパーソナルな組版ソフト。今のInDesignのインターフェースはEdicolorをまねたんじゃないかと思うところもある。ミスターEdicolorが引退したので今後どうかは不安。OCX、AppleScriptでの外部コントロールが可能。レイアウト、文字込みでEdicolorタグで再現可能。ただし、Edianほど再現力はない。その分を外部から制御する感じ。
このレベルでは何でもできそうだが、実際システムの中に組み込むのは実地による実験と検証が必要。スピードもそこそこ。ただし、マシンスペックに大きく左右する。
自動組版させるときは、ドキュメントがオープンするタイプ。
ちなみに上記Edianは開かない。
サーバとして動かすには、上記の会社にご相談ください。
単品の価格は、10万円台のはずだが、InDesignとの比較となると弱い。
PDF出力機能は、単体販売に附属しているが、サーバとしてその機能を使うのは、PDFエンジンの提供会社との契約上NGとのこと。
///MC-B2
モリサワ製品(いつもお世話になってます。)
正式なサーバ版もある。VB(VBScript)でコントロールできる。
もともとが、テキストベースで作業を行って、組版に反映させるタイプの組版エンジンであり、ローカルオペレーションでは、通常のDTPとは違う感覚。レイアウトが決まっているような場合は、B2タグを使って流し込みは可能。レイアウトまでとなると、レイアウト定義ファイルなどを準備する必要がある。
WEB入稿システムとの連携を考えると、事前準備などが多い印象があって、もう少しシンプルにデータを受け付けてくれないと、めんどくさいという印象。サーバ機能として吸収してほしいものだ。PDF出力は機能としてついている。
価格は、単体+オプションで200万円前後。詳しくは販売店に。
ちなみに数式は、フォント屋さんということもあって、仕上がりがキレイ。
あと複雑な表組はオペ的に無理(というかできればB2でやりたくない。)
//WAVE
シンプルプロダクツ製品。(いつもお世話になってます。)
コアはAUTO-CADのエンジンだったと記憶してます。
判断組を得意とするということからも分かりますが、ロジックに基づいて組版するというDTPとは違ったコンセプトのアプリです。なので、他のツールとの連携も普通にアリです。
細かい組版になると、スピードの速さが実感できると思います。(内容によりますが)
自動組版としての機能は普通に持っていて、それをそのまま継承してサーバとして使えると思います。ロジックを作る部分は、それ自体が「人」の頭の中なので、簡単にやろう、と思うのは間違いです。ただ総合的な考え方がすごく面白い。
//InDesign
今、自動組版として注目されてるのは、やっぱりここでしょう。
スタンドアロン利用の価格は10万円を切っているというハイコストパフォーマンス。
ただし、サーバ利用は、結構なお値段。そりゃそうですよね。
それだけあって、サーバ利用の時に役立つAPIも公開されているのでWEB入稿システムとの連携はやりやすそう。あとPDFも出せるしね。
スピードはといえば、ここもマシンスペックに依存すると思われる。実験段階では特に気になることはない。ただ、自動組版ってのは、1日に何千件、何万件処理する可能性があるので、構成的には、最低2台で余裕みて3台のサーバ構成でスタートしないと厳しいかも。
自動組版から考えると、もともとDTPで、「あとこういう機能ついてれば最高なんだけど、、、」というのが結構出てくる。総合的に「惜しい」ので、それが自動組版的にも物足りない部分になってしまっている。いや、それ必要?という意見もあるので、ここで判断する必要はなく、バランスを見る必要はある。
一番の魅力は、クライアントマシンのInDesginもAirとかで制御できてしまえば、サーバ側でやることもない、サーバでもできる、という選択肢が広がる。この辺に傾倒しすぎると、Adobeが神様になってしまうので怖い、というのがいつも不安なだけ。他がなかなか根本的な部分の見直しをかけない(業界が落ち込んでるからかけられない)なか、将来性のある組版エンジンだと思う。た、だ、InDesignをAdobeが「そろそろやめちゃおっかな」となった時点で、普通に使っていると、写●で味わった憂き目と同じ運命を辿るから注意。
しかし、Adobe製品、ソリューションが本社の米国で、かなり「形」になってきているので、すごく楽しみ。やっぱりフォトショやイラレ、ブリッジ、Flex、アクロバットなどなど、連携が始まっていて緩い結合が徐々にされていっている気がして、さすがだなぁと。
//番外 TeX
最強です。
///総合
自動組版エンジンの選択する際に関連する要素といえば、
1.テンプレートが如何に簡単に作れるか、管理できるか。
2.組版スピード
3.ガンガン送っても落ちない安定性
4.PDFが出るか
5.サーバ利用としてのAPIを公開しているか
6.組版がどこまで再現できるか
7.初期コスト、メンテナンスにかかるコスト
8.PDFを配置できるか
9.RIP対応の最終出力ができるか
上記をバランスよくみて、選択する必要があります。
あと、一番重要なのは、メーカーが「それ」用に、如何に準備してくれているか、につきる。
メーカーの協力がなければダメ、言い換えれば「協力してくれるメーカー」でないとダメ。
サーバ版というのは、あらたにサーバとしての機能をつける、というより、
DTPアプリとして開発した部分から、いらないところを削る、ということだけなんだと思うんです。
QXの記事がないのは、知識がなくて自信がないので、決して嫌いだからではないです。
DBパブリッシャーとかあったよねえ。。。
うーん、最近ペースが悪い。
WEB入稿→自動組版→出力の流れに対応できる組版エンジンは、どんなものがあるか、
日進月歩、試行錯誤な毎日ですが、現状ということで。
その筋の方は、コメントして構いませんので、よろしくお願い申し上げます。
///XSLFormatter
アンテナハウス製品(いつもお世話になってます。)
xsl-foの標準仕様+axf拡張で、FOに変換して取り込む。
WEB-Serviceオプションも用意されているので、WEBサービス経由で操作させることも可能。
あとは、コマンドキックとかもできます。
なんといってもPDF出力がデフォなので、PDF出力を最終と考えるなら、
組版→出力の流れは一番速いということになる。
日本語組版的な細かい組版仕様はできないことがある。
最近はまっているのでは、文字のボックスの一部に画像をおいて、そこを排除して文字を回り込ませるあたりは、できないレイアウトがある。
サーバ版という位置づけがこの製品の適切な区分けにはならないと思うが、販売形態としては、スタンドアロン版とサーバ版とある。サーバ版は、1CPUライセンスごと。不特定多数のインターネット利用の場合は、別途の構成がある。
///EdianWing
キヤノンITソリューションズ製品(いつもお世話になってます。キヤノンシステムソリューションズから改名。もとは住友金属。さらに開発しているのは、、、どこだっけ、、、えーと、桐とかの、、、いったことあるんだけど、、、物忘れ激しい、、、あ、管理工学研究所、そうそう)
もともとが、バッチ処理系に長けている製品なので、組版表現は100%(多分)トリガーテキストと呼ばれる文字データで制御できる。
ただし、見た目の判断によるオペレーションレベルまではトリガーテキストではいけない。
ただ、操作制御を行う「スクリプト」なるものがオプションであって、それを使うと、オペレベルのこともスクリプトに書いて実行すれば実現する、というレアな製品。
ちなみに、一般利用としてのAPIは公開されていないが、入稿システムに使うのであれば、WEB2Edian(今もあるのかな)なる、JAVAからソケット通信できるオプションがある。
問題は、価格が高すぎることと、PDFが直接吐けない。
そうなると、組版→EPS(PS)出力→PDF変換でPDF出力となる。
Adobe製品のDistillerをサーバに仕込むとしこたまお金をとられるので、小さい規模の仕組みには使えない。
ただ、結構丈夫なのはすばらしい。組版も速い。
このアプリをDTPとして、他のIDやQXと同等にしか使わないとするなら経営者的にNG。
だって、1台350万円もするんすよ。。。ちなみにうちは10台も20年近く使ってますが、台数の内訳はDTPと自動組版の半々になりましたね。
個人的な愛着もあってNo.1。(表作るの楽だし^^)
///Edicolor
同上の会社製品。地方新聞、広報誌などで現役で戦っておられる。IDへ移行するところもあるが、根強いファンがいるのも事実。
こちらは管理工学研究所ではなく、純日本製のパーソナルな組版ソフト。今のInDesignのインターフェースはEdicolorをまねたんじゃないかと思うところもある。ミスターEdicolorが引退したので今後どうかは不安。OCX、AppleScriptでの外部コントロールが可能。レイアウト、文字込みでEdicolorタグで再現可能。ただし、Edianほど再現力はない。その分を外部から制御する感じ。
このレベルでは何でもできそうだが、実際システムの中に組み込むのは実地による実験と検証が必要。スピードもそこそこ。ただし、マシンスペックに大きく左右する。
自動組版させるときは、ドキュメントがオープンするタイプ。
ちなみに上記Edianは開かない。
サーバとして動かすには、上記の会社にご相談ください。
単品の価格は、10万円台のはずだが、InDesignとの比較となると弱い。
PDF出力機能は、単体販売に附属しているが、サーバとしてその機能を使うのは、PDFエンジンの提供会社との契約上NGとのこと。
///MC-B2
モリサワ製品(いつもお世話になってます。)
正式なサーバ版もある。VB(VBScript)でコントロールできる。
もともとが、テキストベースで作業を行って、組版に反映させるタイプの組版エンジンであり、ローカルオペレーションでは、通常のDTPとは違う感覚。レイアウトが決まっているような場合は、B2タグを使って流し込みは可能。レイアウトまでとなると、レイアウト定義ファイルなどを準備する必要がある。
WEB入稿システムとの連携を考えると、事前準備などが多い印象があって、もう少しシンプルにデータを受け付けてくれないと、めんどくさいという印象。サーバ機能として吸収してほしいものだ。PDF出力は機能としてついている。
価格は、単体+オプションで200万円前後。詳しくは販売店に。
ちなみに数式は、フォント屋さんということもあって、仕上がりがキレイ。
あと複雑な表組はオペ的に無理(というかできればB2でやりたくない。)
//WAVE
シンプルプロダクツ製品。(いつもお世話になってます。)
コアはAUTO-CADのエンジンだったと記憶してます。
判断組を得意とするということからも分かりますが、ロジックに基づいて組版するというDTPとは違ったコンセプトのアプリです。なので、他のツールとの連携も普通にアリです。
細かい組版になると、スピードの速さが実感できると思います。(内容によりますが)
自動組版としての機能は普通に持っていて、それをそのまま継承してサーバとして使えると思います。ロジックを作る部分は、それ自体が「人」の頭の中なので、簡単にやろう、と思うのは間違いです。ただ総合的な考え方がすごく面白い。
//InDesign
今、自動組版として注目されてるのは、やっぱりここでしょう。
スタンドアロン利用の価格は10万円を切っているというハイコストパフォーマンス。
ただし、サーバ利用は、結構なお値段。そりゃそうですよね。
それだけあって、サーバ利用の時に役立つAPIも公開されているのでWEB入稿システムとの連携はやりやすそう。あとPDFも出せるしね。
スピードはといえば、ここもマシンスペックに依存すると思われる。実験段階では特に気になることはない。ただ、自動組版ってのは、1日に何千件、何万件処理する可能性があるので、構成的には、最低2台で余裕みて3台のサーバ構成でスタートしないと厳しいかも。
自動組版から考えると、もともとDTPで、「あとこういう機能ついてれば最高なんだけど、、、」というのが結構出てくる。総合的に「惜しい」ので、それが自動組版的にも物足りない部分になってしまっている。いや、それ必要?という意見もあるので、ここで判断する必要はなく、バランスを見る必要はある。
一番の魅力は、クライアントマシンのInDesginもAirとかで制御できてしまえば、サーバ側でやることもない、サーバでもできる、という選択肢が広がる。この辺に傾倒しすぎると、Adobeが神様になってしまうので怖い、というのがいつも不安なだけ。他がなかなか根本的な部分の見直しをかけない(業界が落ち込んでるからかけられない)なか、将来性のある組版エンジンだと思う。た、だ、InDesignをAdobeが「そろそろやめちゃおっかな」となった時点で、普通に使っていると、写●で味わった憂き目と同じ運命を辿るから注意。
しかし、Adobe製品、ソリューションが本社の米国で、かなり「形」になってきているので、すごく楽しみ。やっぱりフォトショやイラレ、ブリッジ、Flex、アクロバットなどなど、連携が始まっていて緩い結合が徐々にされていっている気がして、さすがだなぁと。
//番外 TeX
最強です。
///総合
自動組版エンジンの選択する際に関連する要素といえば、
1.テンプレートが如何に簡単に作れるか、管理できるか。
2.組版スピード
3.ガンガン送っても落ちない安定性
4.PDFが出るか
5.サーバ利用としてのAPIを公開しているか
6.組版がどこまで再現できるか
7.初期コスト、メンテナンスにかかるコスト
8.PDFを配置できるか
9.RIP対応の最終出力ができるか
上記をバランスよくみて、選択する必要があります。
あと、一番重要なのは、メーカーが「それ」用に、如何に準備してくれているか、につきる。
メーカーの協力がなければダメ、言い換えれば「協力してくれるメーカー」でないとダメ。
サーバ版というのは、あらたにサーバとしての機能をつける、というより、
DTPアプリとして開発した部分から、いらないところを削る、ということだけなんだと思うんです。
QXの記事がないのは、知識がなくて自信がないので、決して嫌いだからではないです。
DBパブリッシャーとかあったよねえ。。。
登録:
投稿 (Atom)